GTC 2014:後記,大數據、資料分析與機器學習

今年的NVIDIA GTC 的主題演講上,執行長黃仁勳花了不少的時間講述機器學習;機器學習在近年成為許多大規模企業的必修課程,許多網路公司開始聘請專業團隊進行機器學習的研究,如同主題演講提到Google 也已經著手大腦的模擬開發。
機器學習是甚麼?簡單說就是透過反覆接收資訊的方式,讓機器去進行學習的行為。這樣的概念可以追溯到如汽車的學習型自動變速箱,透過接收駕駛踩油門習慣的資訊,逐漸調整變速箱換檔的方式;而機器學習到了當今的網際網路時代,又產生新的定義。

網路時代的機器學習,是建立在以大數據為基礎的模式,並且結合資料分析的方式,以模擬人的感官為目標的機器學習。網路時代的機器學習與早期的封閉式機器學習最大的差異在於資料量的差異,每天網路資訊產生的數據遠遠大於個人,把這些資訊有用的部分分類並且建立行為模式,就會產生一定程度的人工智慧。
舉例來說,如何從照片的人臉分辨男性與女性?首先提供機器大量的男性與女性照片作為學習的基礎材料,讓機器由樣張進行影像分析,獲取男性與女性照片的特徵,並由此產生一套辨識機制,例如顴骨的特徵,五官的分佈比例,眼睛的形式等,而後把系統投入照片庫開始進行實際操作,並且再從分辨的過程持續修正。

另外一個例子則是搜尋引擎,筆者不確定 Google 的運作模式,不過從 Google 所提供的關鍵搜尋、推薦搜尋,也可視為一種機器學習的過程。從使用者的搜尋與閱覽行為進行分析,可以從這些資訊中發掘搜尋特定關鍵字的使用者到底使用這些關鍵字找些甚麼、對甚麼內容產生興趣,只要再把這些資訊進行剖析,就能讓關鍵字的關聯更精確。
最簡單的成果,就如同搜尋關鍵字不小心打錯字時,系統提出的建議正確文字,或是搜尋資料時,系統提供的關鍵字廣告,或者搜尋資料時,旁邊另外提供的”你也許有興趣的相關搜尋”,且藉著機器學習資料庫上線時間越久,也會發現提供的資訊精確度越來越高。
另外,主題演講還提到推特透過數據分析與機器學習的方式,以推特上的颶風討論串推測颶風動向,感覺推特訊息與颶風動向八竿子打不著,推特是怎從中進行預測?筆者推測,推特先將颶風設為關鍵字,接著從發文者的 IP 位置進行分類與過濾,進行颶風所在地的推測,接著把推測出來的位置畫成路徑,而後就可透過這些資訊進行颶風行徑路線的推測。
當然,氣象與天災預報也是機器學習相當重要的一環,早期的天氣預測多半是由氣象分析師從衛星資料判斷未來的天氣;然而以機器學習的方式,則是以過往的天氣徵兆、地理特性、季節特性等資訊做為基礎,以過去的資訊為師,進而得以預測未來。
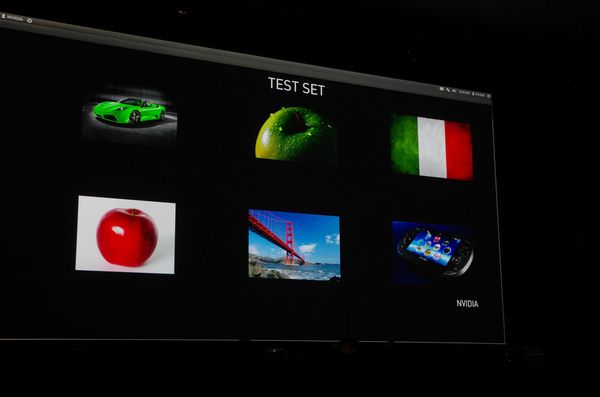
然而機器學習要能取代人的判斷還有很長遠的路要走,畢竟機器學習目前還是透過大量資料推斷出合理的資訊,但合理的答案不見得代表是好的答案。這話怎說?就像為了一天的健康打造的食譜,如果只求合理的營養,那得到的餐點配置恐怕是一份食之無味的原料餐;但好的答案則是把這些營養資料重新組合,獲得一份美味與營養兼具的餐點。
為何 NVIDIA 今年會如此重視機器學習?實際上近年的機器學習伺服器架構與 GPU 是密不可分的,因為機器學習基本上是把大量的素材進行分類與解析,如同社群網站的大量關鍵字分類、圖片庫的影像分析等,使用 GPU 與 CPU 的平行運算方式會遠比純 CPU 效率來的更高,是故近年多數的機器學習都是轉以平行運算架構。

然而, NVIDIA 自從推出 GeForce Titan 產品線之後,將具備高效能運算的架構帶到個人領域,也成為一般消費者、小型研究室有辦法負擔的價位,且加上平行運算的演算法越來越成熟且容易,例如後來推出的 Open ACC ,只要加入兩行註解,就可把現有的演算法轉化為支援 CUDA 平行運算的演算法。
筆者認為, NVIDIA 在今年的 GTC 特別於發表 Titan Z 前介紹機器學習,就是希望能透過 Titan Z 的強大運算力,壯大機器學習的開發,讓機器學習不再只是大企業的獨門研究,讓對機器學習有想法的開發者也能透過平價的硬體進行開發。
畢竟機器學習不單只是硬體方面的事情,軟體也是機器學習的大事,如何有效的進行關鍵字解析、自主進行學習、以朝向更接近人的思維為目標,並且把硬體的效率盡可能提升,在更多人集思廣益下,讓機器學習步入下一個階段。
延伸閱讀:






















![[Cydia教學]告別沒質感的iOS 7: 超美超細緻的”Jaku”圖示主題](https://www.iarticlesnet.com/pub/img/article/3596/1403796883257_xs.jpg)



